Clean Architecture
- Nick
- 19 March 2022
Clean Architecture
Best Practices
Clean Architecture is a set of practices used to create modern software architecture that is simple, understandable, flexible, testable, and maintainable. In addition clean architecture is more modern replacement for the traditional three layered database-centric architecture that is been used for decades.
Clean architecture is an architecture designed for the inhabitants of the architecture, not for the architect or for the machine. Clean architecture is a philosophy of architectural essentialism. It's about focusing on what is truly essential on the software's architecture versus what is just an implementation detail. By designing for the inhabitants we mean the people that will be leaving within the architecture during the lifetime of the project. This means the users of the system, the developers building the system and the developers maintaining the system.
Clean architecture is useful for enterprise applications. That is, applications designed to solve business problems. Statistically these type of applications are the majority in the day to day work.
Clean Architecture is build to support agile software development process. That is, building software in an iterative and evolutionary manner.
Domain Centric Architecture
In the past we all knew that the earth is at the center of the solar system and the sun, the moon, and the planets revolve around the earth. Correct? They don't anymore, but they did at one time. Nicolaus Copernicus changed the way we look at our solar system. Rather than assuming that the earth was at the center of the solar system, he said that the sun is at the center and not the earth. This shift in perspective turned out to be a better model of the solar system, in sense that it's both simpler, and yet it provides more explanatory power. It is essentially more elegant model of our solar system.
A similar shift in thinking is happening in the world of software architecture. Below we have a classic three-layer database-centric architecture.
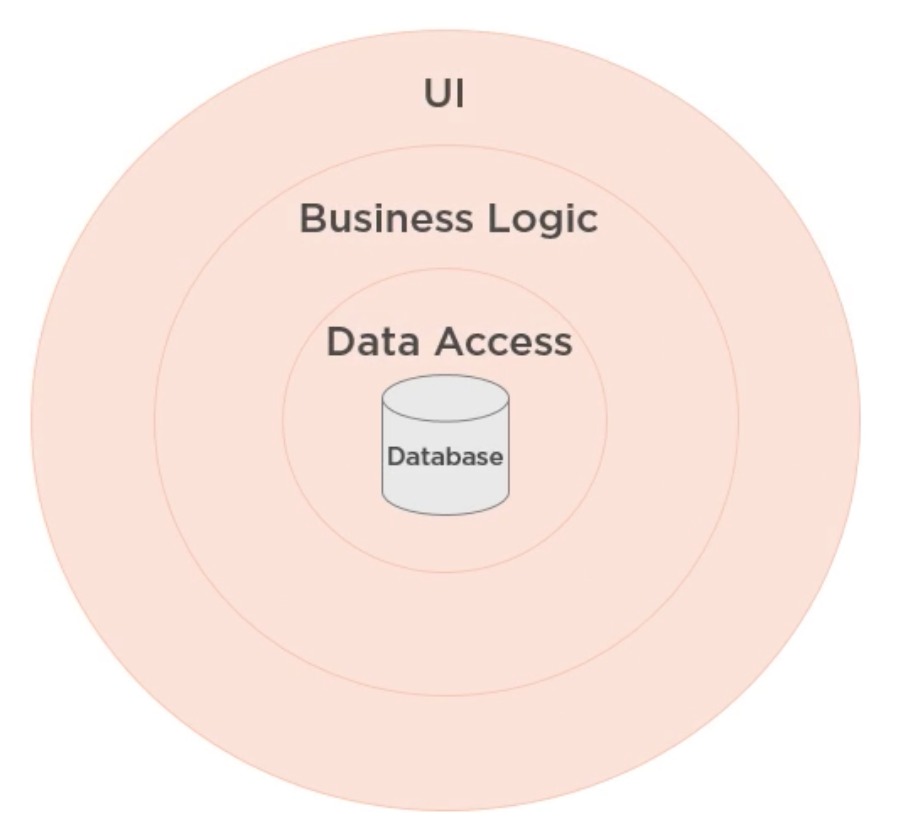
It's key feature is that the user interface, business logic and data access layer revolve around the database. The database is essential and thus it's the center of this architecture
However, a new perspective has changed the way many of us look at our architecture. Rather than having the database at the center of our architecture, clean architecture puts the domain at the center of our architecture and makes the database an implementation detail outside of the architecture. Here the domain is essential, and the database is just a detail. This change of perspective is best summed up by a quote from Robert C.Martin, better known as uncle Bob. He says:
"The first concern of the architect is to make sure that the house is usable, it is not to ensure that the house is made of brick."
This change in architectural perspective is being caused by a change in perspective about what is essential in an architecture versus what is just an implementation detail.
Using our building architecture metaphor, when we're building a house what is essential versus what is a detail? The space inside of a house is essential. Without empty space to inhabit the house would serve no purpose. The usability of the house is essential. If the house didn't contain rooms and features to support our primary needs, again, the house would not serve it's purpose. However the building material is just an implementation detail. We could build it out of brick, stone, wood or many other materials. The things that are essential in a house are so because they support the primary needs of the inhabitants of the house. Everything else is just an implementation detail.
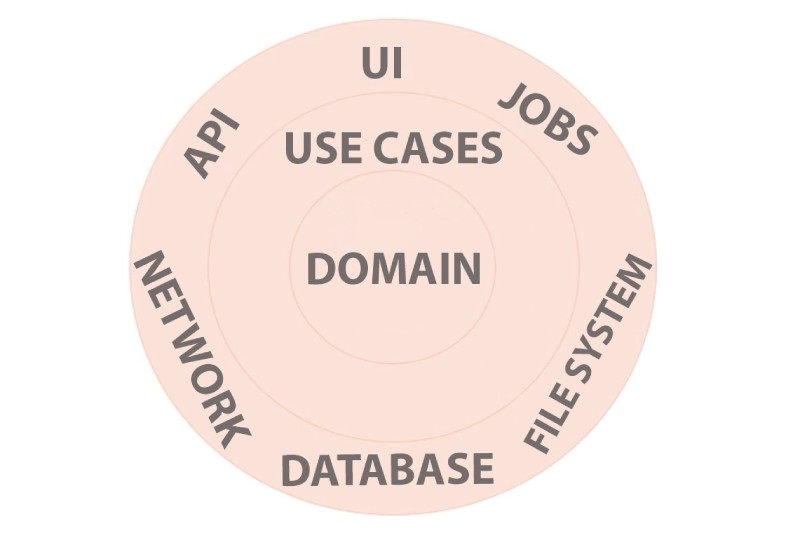
In clean architecture what is essential are the things that support the primary needs of the inhabitants of the architecture. The domain model is essential. Without it the system would not represent the mental models of the user. The use cases are essential. Without them the system would not solve the user's problems. However database is just a detail. We can persist our data in relational database, or in a no SQL database, or just plain old JSON files. The presentation layer is a detail. We can deliver the UI in web forms, ASP.NET MVC or as a single page JavaScript application.
The image below shows the clean architecture diagram:
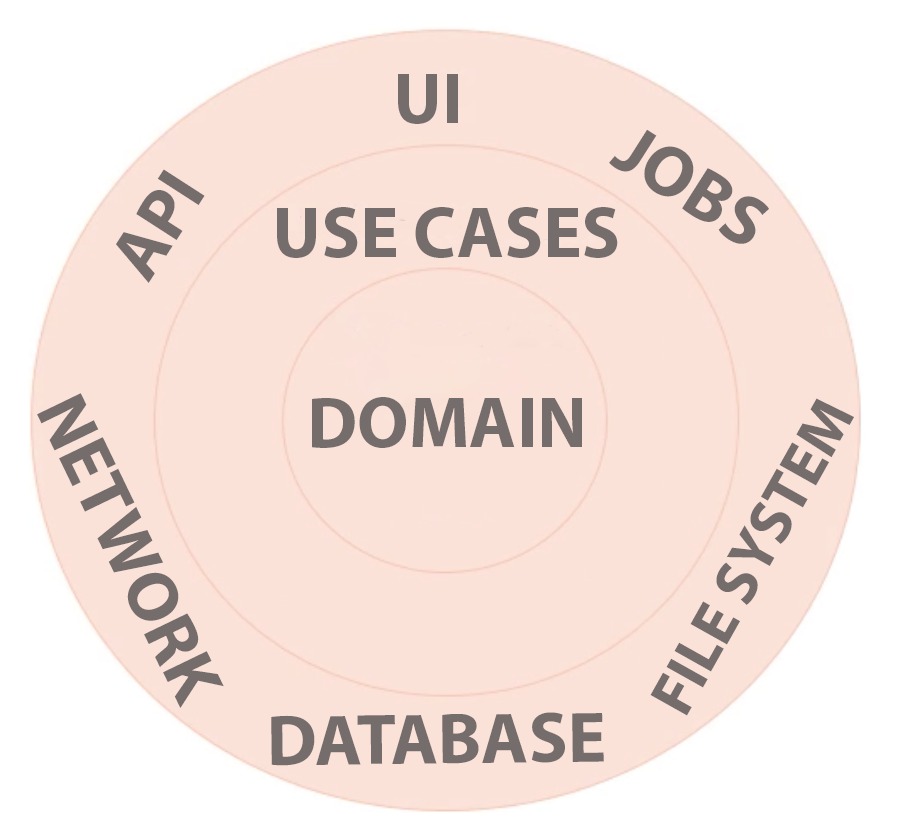
Benefits of Domain Centric Architecture
There are several benefits using domain centric architecture:
- Focus is placed on the domain which is essential to the inhabitants of the architecture, that is the users and the developers.
- There is less coupling between the domain logic and the implementation details, for example, the presentation, database, and operating system. This allows the system to be more flexible and adaptable, and we can much more easily evolve the architecture over time.
- Using a domain-centric architecture allows us to incorporate Domain Driven Design, which is a great set of strategies by Eric Evans for handling business domains with high degree of complexity.
Command-Query Separation
In 1988 Bertand Meyer taught us that there were two kinds of methods in object oriented software. First we have a command. A command does something which means modifies the state of the system. Next we have query. A query answers a question which means it should not modify the state of the system and should return a value. Bertand told us that we should attempt to separate command query where possible. There are several reasons why this is a good idea. For example, to avoid nasty side effects that hide in methods that violate this principle.
CQRS(Command and Query Responsibility Separation) Architectures
CQRS expand this concept of command query separation to the architectural level. In general, we're dividing the architecture into a command stack, and a query stack. This is done for various reasons. The primary reason is that queries should be optimized for reading data, whereas commands should be optimized for writing data. Commands execute commands in the domain model, mutate state, raise events, and write to the database. Queries use whatever means is most suitable to retrieve data from the database, transform data in format for presentation and display it to the user. This change increases both the performance of the commands and queries, but equally important, it increases the clarity of the respective code.
CQRS is domain-centric architecture done in smart way. It knows when to talk to the domain via commands, and when to talk directly to the database via queries.
There are 3 types of CQRS:
- Single-database CQRS. This type has a single database that is either a third normal form relational database or some type of NoSql database. Commands execute behavior in the domain, which modifies the state, which is then saved to the database through the persistence layer, which is often an ORM. Queries are executed directly against the database using a thin data access layer, which is either an ORM, Sql scripts or stored procedures.
- Two-database CQRS. This type of CQRS has both read database and a write database. The command stack has it's own database optimized for write operations. For example, a third normal form relational database or a NoSQL database. The query stack, however, uses a database optimized for read operations. For example, a first Normal Form relational database or some other denormalized read optimize data store. The modifications to the write database are pushed into the read database either as a single coordinated transaction across both database or using an eventual consistency pattern. That is, the two databases may be out of sync temporarily, but will always eventually become in sync, typically on the order of milliseconds.
This is more complex than the first, but can afford orders of magnitude improvements in performance on the read side of the system. This makes quite a bit of sense because we generally spend orders of magnitude more time reading from a database than we do writing to it.
- Event Sourcing CQRS. The main difference here is that we do not store the current state of our entities in a normalized data store. Instead, we store just the state modifications to the entities over time, represented as events that have occurred to the entities. We store this historical record of all events in a persistence medium called an event store. When we need to use an entity in its current state we replay the events that have occurred to that entity, and we end up with the current state of the entity. Then once we've reconstructed the current state of the entity we execute our domain logic, and modify the state of the entities accordingly. This new event will be stored in our event store that can be replayed as needed. Finally, we push the current state of our entity out to the read database, so our read queries will still be extremely fast.
This is the more complex of the three types of CQRS but comes with some benefits. First, since the current state of each can only be derived by replaying the sequence of events that have occurred to that entity, the event store acts as a complete and guaranteed to be true audit trail for the entire system. This is highly valuable in heavily regulated industries where this type of auditability is necessary. Second, we can reconstruct the state of an entire entity at any point in time. This is useful for determining what the state of an entity was at any previous point in time in the system, and this is also very useful for debugging. Third, we can replay events to observe what happened in the system. This is very useful for diagnostics and debugging. In addition this is very useful for load testing and regression testing in a test environment using existing production events that have occurred in the system.
Benefits of CQRS
There are several benefits using CQRS architecture:
- If your are implementing domain driven design, implementing CQRS is more efficient from a coding perspective. Commands are coded to use the rich domain models to modify state, and queries are coded directly against the database to read data.
- By using CQRS we're optimizing the performance of both the query side and the command side for their respective purposes. Depending upon which type of CQRS we implement, this can mean orders of magnitude improvements in performance.
- As system become more complex or require high degree of auditability event sourcing features can become highly valuable to both the business and to the developers.
Screaming Architecture
The screaming architecture practice is based on that your software's architecture should scream the intent of the system, hence the name screaming architecture. We do this by organizing our architecture around the use cases of the system. Use cases are representations of a user's interaction with the system. For example, interactions like getting a list of all customers, purchasing a product or paying a vendor.
The screaming architecture practice can best be explained using a metaphor about the architecture of buildings. In buildings the blueprints represents the intent of the architecture. Let's take a look the following blueprint of a house.
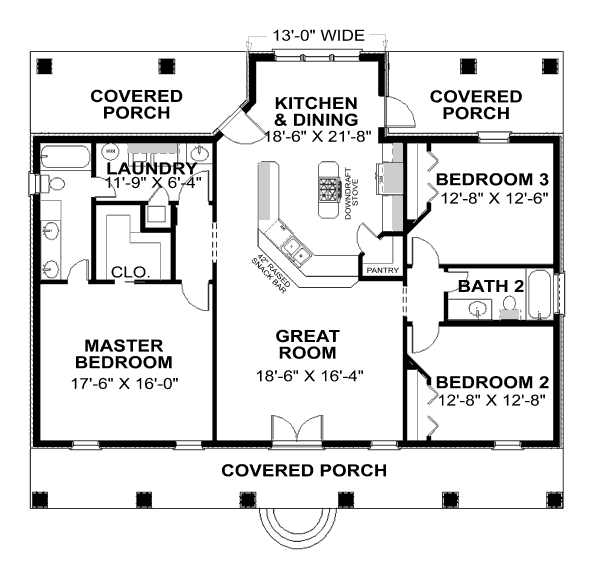
It is pretty easy for us to understand the intent of this architecture by quickly scanning across the blueprint. This is clearly the blueprint for a residential building of some kind, and the intent of this architecture is to facilitate a residential living environment. The rooms of this building embody the use cases of the building. We sleep in a bedroom, we cook in kitchen, we eat in a dining room, and so on. Simply by looking at the rooms contained in an architectural blueprint, which represent the use cases of the building, we can quickly determine the function and intent of the architecture of the building.
The relationship between the organization of software architecture and the ease of discovering the intent of the architecture is governed by similar principles. We can organize our application's folder structure and namespaces according to the components that are used to build the software, components like models, views, and controllers, or we can organize our folder and namespaces according to the use cases of the system, concepts that pertain to user's interaction with objects in the system like customers, products, and vendors. For example let's take a look two representations of the same software architecture:
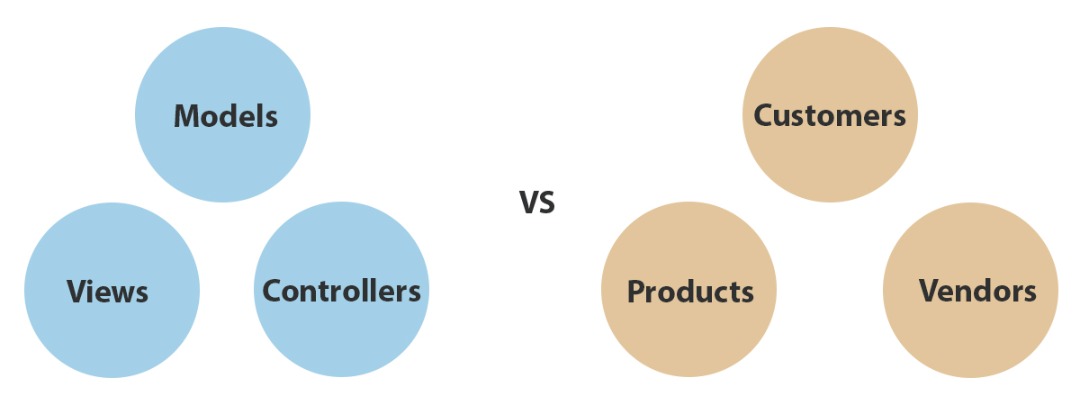
On the left we have the typical MVC. Things we all recognize as MVC components, like models views, and controllers. On the right however, we have the same web application organized by its high-level use cases like customers, products, and vendors. It's very difficult to determine the intent of the software on the left, but it's much easier to determine the intent of the software on the right.
Benefits of Screaming Architecture
There are several benefits using Screaming architecture:
- When we organize by function we utilize the principle of special locality, that is items that are used together live together.
- Second, it's much easier to find things and navigate the folder structure. If we want to work with the customer objects, like the employee models, views, and controllers, we just navigate to the employees folder in the presentation layer, and they're all contained in that folder.
- It helps us to avoid vendor and framework lock in because we're not forced into the folder structure that the vendor insist that we use to implement their framework.
Microservices
Microservices architectures subdivide monolithic applications, that is they divide a single, large application into smaller subsystems.
These microservices communicate with one another using clearly defined interfaces, typically over lightweight web protocols, for example, JSON over HTTP via rest APIs.
Microservices can also subdivide larger teams into smaller development teams, that is, one team for each microservice or set of microservices.
These services are also independent of one another. Each one can have it's own persistence medium, programming language, architecture, and operating system. In addition you can independently deploy each microservice and independently scale them as needed, which is very beneficial for cloud scale applications.
Microservices are similar in concept to service oriented architecture, however, they don't explicity prescribe the use of an enterprise service bus, along with several other key differences.
Bounded context
Two very frequent questions that often come up when discussing microservices are how big should each microservice be? and where should i draw the boundaries of each microservice? This is where bounded contexts come in.
Microservices have a natural alignment to the boundaries of bounded contexts. Ideally, in most cases we want each domain, each microservice, each database, and each corresponding development team to line up. Doing so provides several benefits. For example, this maximizes the cohesion of the domain entities in each bounded context and minimizes the coupling relative to any other way we could have partitioned the system.
In addition, this allows each team to focus on only a single domain of knowledge. They don't need to know about the intimate details of any other team's domain, database or microservice. They just need to know how to communicate with the well-defined interfaces of those other microservices. This also means that each domain domain and microservice has a consistent data model, that is, all entities contained within a bounded context are consistent with one another, even if they are temporarily inconsistent with other microservices using an eventual consistency model.
Within each microservice each team can use whatever technologies, patterns, practices or principles work best to solve the specific business problems of their domain according to the specific constraints and business objectives of their respective microservices. This could entail using different architectures, persistence mediums, programming languages or even operating systems for each individual microservice based on the specific needs of that domain, and the knowledge and skills of each development team. This is highly valuable for agile software development teams using agile practices to develop large business applications.
Benefits of Microservices
There are several benefits using microservices:
- The cost curve of microservices is flatter than the cost curve of monolithic applications as a function of size of the system being build. That is, the cost to build microservices is initially higher than monoliths for small systems, but the cost of building microservices grows much more slowly as the system gets bigger, so for projects with large domains and sufficiently long life cycles, using microservices in this context can, in theory, reduce the overall cost of project.
- Subdividing a monolithic application into microservices based on bounded contexts, creates systems with high cohesion and low coupling. This isn't in terms of the cohesion and coupling in our code base, but also high cohesion and low coupling for our development teams, domain knowledge, database models, and more.
- Microservices offer independence. Essentially, you can use whatever technologies, design patterns, and development practices are most appropriate for each specific microservice and corresponding team.
Testable Architecture
There are numerous reasons why developers don't create high quality automated tests for their code. These reasons include:
- Developers say they do not have enough time to create tests.
- Developers think it is not their job to create tests. Testing is for testers.
- Developers say it's too hard to create good tests because the architecture they are using makes testing difficult.
We are going to show how clean architecture actually makes testing easier not harder for testing. In addition, how test driven development drives the design of a clean architecture. These two forces work side by side to create a feedback loop that feeds into one another.
Test Driven Development(TDD)
TDD is a software practice where we create a failing test first before we write any production code, and use this test to drive the design of the architecture. We refer to this three-step process of TDD as red, green, refactor.
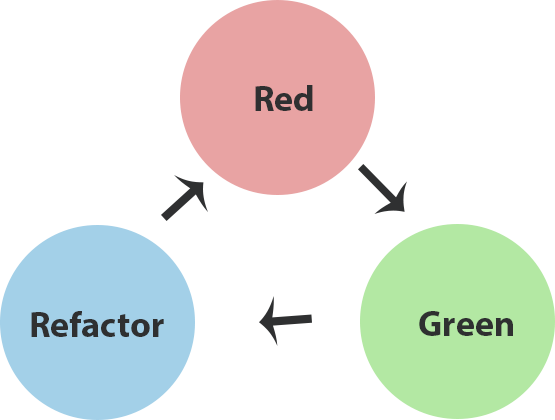
- Red: Create a failing test for the simplest piece of functionality we need to create.
- Green: Implement just enough production code to get that failing test to pass.
- Refactor: Refactor existing code, that is, we improve both the test and production code to keep the quality high.
We repeat this cycle for each piece of functionality in order of increasing complexity, in each method and class until the entire feature is complete.
By using the TDD practise we are creating a comprehensive suite of tests that covers all code passive importance in our application.
In addition, by using TDD the design of each of these classes and methods is being driven by the testing process. This means that all classes and methods will be easily testable by default, since the tests are driving the design.
In addition, this coincidentally makes our classes and methods more maintainable because of an interesting parallel in the physics of cohesion and coupling with both testability and maintainability. Essentially, by creating testable code we are coincidentally creating more maintainable code.
More importantly, this comprehensive suite of tests eliminates fear, fear that making changes to our code will cause regression errors in our software. If we can eliminate the fear of change in our architecture we are more likely to embrace change and keep our architecture clean.
TDD is a key component to creating a clean and testable architecture!
Types of Tests
In the book, Succeeding With Agile, Mike Cohn describes a concept he referred to as the test automation pyramid:
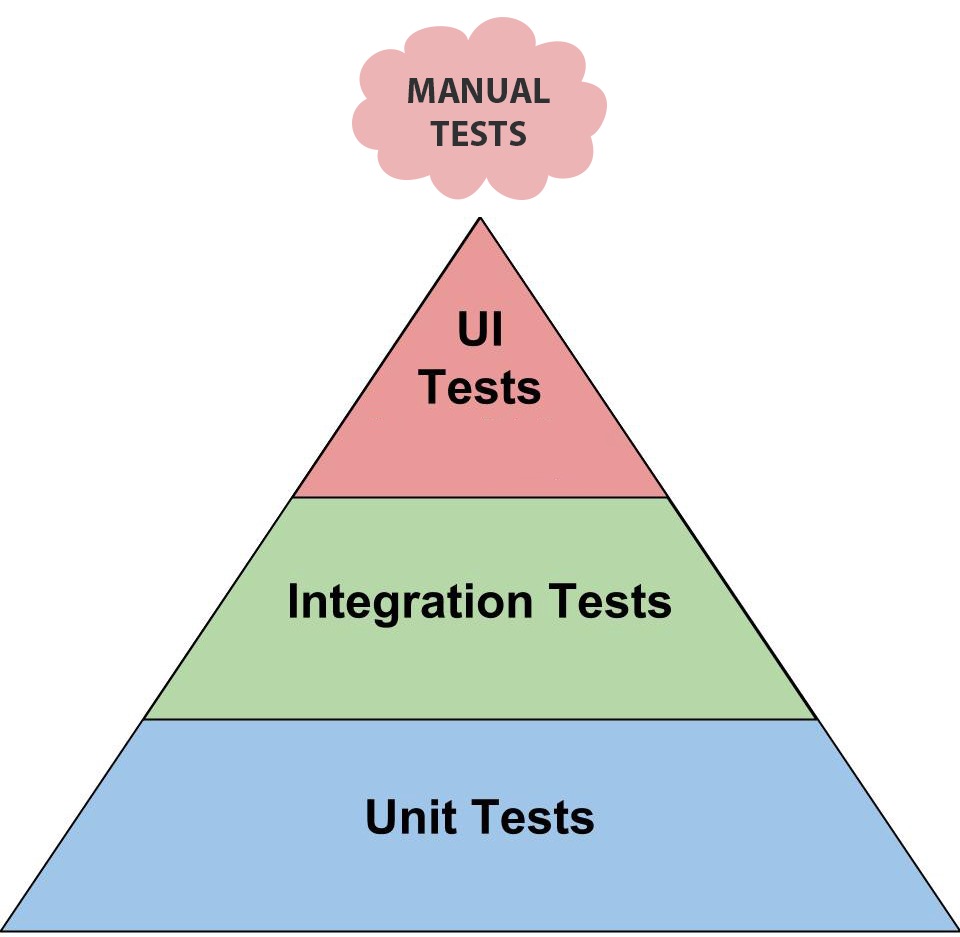
The test automation pyramid identifies four types of tests:
- Unit Tests: Are automated tests that verify the functionality of an individual unit of code in isolation.
- Integration Tests: Are automated tests the verify the functionality of a set of classes and methods that provide a service to the users.
- UI Tests: Are automated tests that verify the functionality of the full application from the user interface down to the database.
- Manual Tests: Are tests performed by a human that verify the functionality of the full application.
The test automation pyramid captures the essence that each type of test becomes more costly the further up the pyramid we go. As a result, we want to have a large number of low costs tests and a small number of high cost tests. For example, unit tests are relative quick and easy to create, run extremely fast, rarely fail, are inexpensive to maintain, so they are much less costly than the other types of tests.
UI tests are much more difficult and time consuming to create. They also run much slower, they 're more brittle, relatively unreliable, and relatively more difficult to maintain. So they relatively more costly than other types of test lower on the pyramid.
Given this we want to maximize the return on investment from our testing efforts by creating the right balance of type of test relative to the cost of the test, and the benefit that the test will provide, so we should anticipate creating lots of small, low cost unit tests, some medium cost integration tests, a few high cost UI tests, and very few repetitive manual tests. Doing so, in theory, gives us the most bang for the buck for our testing efforts.
Benefits of Testable Architecture
There are several benefits using testable architecture:
- By applying testable application practices we make our code easier to test, this will help us to create and maintain these tests. We want our architecture to encourage developers to write tests and to practice TDD.
- Creating testable architecture improves the design of our architecture. This is because the physics of cohesion and coupling of testable code parallels that of maintainable code. So, by virtue of adopting TDD, and creating a testable architecture we're actually creating a more maintainable architecture as a result.
- By creating a comprehensive suite of tests for our architecture we eliminate fear. By eliminating fear that changes to our code will break the code we're much more likely to embrace change, continuously refactor our code to improve it, and keep our architecture clean.
Evolving the Architecture
The methods above are a starting point for building modern applications that will benefit from this set of practices. These are typically applications built using agile software development practices in an environment with a high degree of risk due to uncertainty and changing requirements caused by changing technologies, changing markets, and changing user preferences. This means that the architecture needs to evolve to minimize this risk due to uncertainty, and meet these changing requirements.
By placing focus on the key abstractions of the domain and application of logic at the center of the architecture, and deferring user interface, persistence, third party dependencies, and cross-cutting concerns to implementation details, clean architecture allows the application to more easily evolve over time. When we're making these implementation decisions we want to defer these decisions until the moment known as the last responsible moment. This term was coined by Mary and Tom Poppendieck in the book, Lean Software Development: An Agile Toolkit.
The Last Responsible Moment is a strategy for avoiding making premature decisions by deferring important and difficult to reverse decisions until a point in time where the cost of not making the decision becomes greater than the cost of making the decision. By delaying these until the last responsible moment we increase the likelihood that we are making well informed decisions because we now have more information. Making implementation decisions too early can be a huge risk on some projects, however, waiting until after the last responsible moment, as the name implies, creates potential risks and technical debt as well. Evolutionary architecture practices are about creating architecture that allows us to more easily defer these decisions until the moment where we've minimized the risk due to making the decision too early, but not waited too long, and accumulated technical debt. For example by focusing on the domain and application logic, and solving the key problems that our users need to solve, we can validate whether or not our software will actually provide real business value to our users before we invest heavily in the implementation details. In meantime, we can just use the simplest solution that could possibly work for each of the implementation details, just enough to get us by while we validate the primary value proposition of the application, that is whether or not our software will provide real business value to our users and our business.
In addition, technology will likely change over the life of the project. For example, during the course of a project a new type of database technology may eventually be released, that makes more sense than using the database technology that we'd previously decided upon. Clean architecture makes it much easier to defer implementation decisions or replace existing implementation than an architecture built around a specific implementation.
Markets may also change over the life of a project as well. For example, a simple client server application to support a few hundred users might balloon in demand to millions of users and need cloud scale, CQRS, and microservices to support thew new workload. With clean architecture we build a solid domain and application core first, and then scale that core as large necessary, if and when the need should arise.
User preferences may also change over the life of a project as well. For example, we might discover later on in the project that users now want a mobile user interface rather than the desktop user interface that they had previously desired. With this style of architecture we can easily swap our presentation technologies or support multiple user interfaces built upon the key abstractions in the domain and application layer. We want our application architecture to be flexible by default to help protect us against the unpredictability of the future. These architectural patterns, practices, and principles that we've just learned give us this kind of flexibility and adaptability.
Benefits of evolutionary architecture
There are several benefits using evolutionary architecture:
- Embrace uncertainty: If you are building an application in an environment with a high degree of uncertainty it's better to have an architecture that can evolve as you learn more over time than to try to predict the future and build a rigid architecture based on those, likely to be wrong, predictions.
- Embrace change: It's inevitable that on most software projects the requirements will change over the life of the project. Having flexible architecture allows the architecture to adapt to these changes.
- Reduce risk: If uncertainty or changing requirements are the biggest risk to your project, which is the case with most projects, then optimizing you architecture for adaptability helps you to reduce this risk.
It is important to be aware that there are obviously limitation to the flexibility of clean architecture. It can't work miracles but it's still significantly more adaptable and maintainable than any of the more traditional styles of architecture.